Model Information






Description
这个链接下包含 STEPFUN-AI 发布的 ACEStep & Step1XEdit

ACEStep Music Generation
ACEStep 是一款由 ACE Studio 与 StepFun 联合开发的音乐生成模型,被誉为“音乐界的Stable Diffusion”。该模型以其惊人的生成速度和多样化功能引发行业热议,能够在短短20秒内生成一首长达4分钟的完整音乐作品,效率比主流模型快15倍以上
技术特点和应用场景
ACEStep基于 DiT(Diffusion Transformer)架构,采用轻量化设计,支持在消费级GPU上运行,显著降低了硬件门槛。该模型支持19种语言,包括英语、中文、日语、西班牙语等,为全球音乐创作者提供了广泛的适用性
ACEStep的核心功能包括:
歌词驱动创作:输入歌词,模型自动生成旋律并演唱完整歌曲。
风格化编曲:根据指定的风格标签(如说唱、电子乐、流行等),自动生成伴奏和配器。
精准修改:支持对歌曲某段歌词进行修改,而不影响原有旋律的连贯性。
多样化生成:能够生成带风格的说唱、电子乐、人声或复杂配器,满足不同音乐场景需求
最新动态和未来发展前景
ACEStep 通过GitHub(stepfun-ai/Step-Audio)向开发者开放,允许社区对其进行微调以适配多样化的音乐任务。
Step1XEdit image editing model
RED版节点包及示例工作流,支持 Step1XEdit,自定义注意力机制,16G 显存占用。
RED nodes package and sample workflow, supports Step1XEdit, custom attention mechanism, and occupies 16GB of video memory.
此自定义节点将 Step1X-Edit 图像编辑模型集成到 ComfyUI 中。Step1X-Edit 是一个先进的图像编辑模型,它接收参考图像和用户的编辑指令,生成新的图像。
RED nodes for Step1XEdit, custom attention mechanism with 16GB of video memory usage. This custom node integrates the [Step1X-Edit] image editing model into [ComfyUI]. Step1X-Edit is a state-of-the-art image editing model that processes a reference image and user's editing instruction to generate a new image.
Step1X-Edit 基于FLUX 模型规格,但是替换了文本编码器为Qwen2.5-VL 7B
模型权重为重新训练,与BSL的 FLUX.1 授权协议没有继承关系
License:apache-2.0
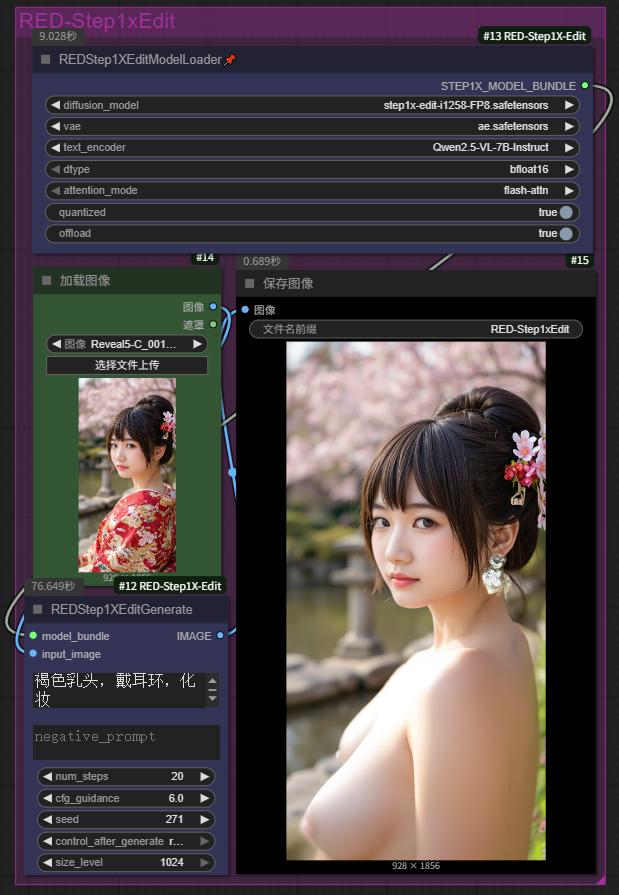
主要特性
支持多种注意力实现方式(Flash Attention 2, PyTorch SDPA, Vanilla)
灵活配置以适应不同硬件能力
优化性能和兼容性
功能特点
支持 FP8 推理
支持自定义注意力实现(Flash/PyTorch(SDPA)/Vanilla)
无需折腾安装Flash Attention2(如有需要可自行安装)
代码仓库
https://github.com/QijiTec/ComfyUI-RED-Step1X-Edit
forked from raykindle/ComfyUI_Step1X-Edit
🔥 原作者新加入了Teacache加速器支持(需要Flash-attn2)
模型仓库(CivitAI 页面可以直接下载)
Step1X-Edit 扩散模型:从 HuggingFace 下载
step1x-edit-i1258-FP8.safetensors并放置在 ComfyUI 的models/diffusion_models目录中Step1X-Edit VAE:从 HuggingFace 下载
vae.safetensors并放置在 ComfyUI 的models/vae目录中 (等同于FLUX diffusers 版VAE)Qwen2.5-VL 模型:下载 Qwen2.5-VL-7B-Instruct 并放置在 ComfyUI 的
models/text_encoders/Qwen2.5-VL-7B-Instruct目录中
Download Step1X-Edit-FP8 model
Step1X-Edit diffusion model: Download
step1x-edit-i1258-FP8.safetensorsfrom HuggingFace and place it in ComfyUI'smodels/diffusion_modelsdirectoryStep1X-Edit VAE: Download
vae.safetensorsfrom HuggingFace and place it in ComfyUI'smodels/vaedirectoryQwen2.5-VL model: Download Qwen2.5-VL-7B-Instruct and place it in ComfyUI's
models/text_encoders/Qwen2.5-VL-7B-Instructdirectory
Configure the model parameters
Select
step1x-edit-i1258-FP8.safetensorsas the diffusion modelSelect
vae.safetensorsas the VAESet
Qwen2.5-VL-7B-Instructas the text encoderSet additional parameters (
dtype,quantized,offload) as needed
🔥🔥🔥🔥🔥🔥 stepfun-ai/Step1X-Edit🔥🔥🔥🔥🔥🔥

Step1X-Edit: a unified image editing model performs impressively on various genuine user instructions.
Model introduction

Framework of Step1X-Edit. Step1X-Edit leverages the image understanding capabilities of MLLMs to parse editing instructions and generate editing tokens, which are then decoded into images using a DiT-based network.More details please refer to our technical report.
Benchmark
We release GEdit-Bench as a new benchmark, grounded in real-world usages is developed to support more authentic and comprehensive evaluation. This benchmark, which is carefully curated to reflect actual user editing needs and a wide range of editing scenarios, enables more authentic and comprehensive evaluations of image editing models. Part results of the benchmark are shown below:

Citation
@article{liu2025step1x-edit,
title={Step1X-Edit: A Practical Framework for General Image Editing},
author={Shiyu Liu and Yucheng Han and Peng Xing and Fukun Yin and Rui Wang and Wei Cheng and Jiaqi Liao and Yingming Wang and Honghao Fu and Chunrui Han and Guopeng Li and Yuang Peng and Quan Sun and Jingwei Wu and Yan Cai and Zheng Ge and Ranchen Ming and Lei Xia and Xianfang Zeng and Yibo Zhu and Binxing Jiao and Xiangyu Zhang and Gang Yu and Daxin Jiang},
journal={arXiv preprint arXiv:2504.17761},
year={2025}
}ComfyUI nodes-ACESTEP Music Generation & Step1X-Edit ComfyUI组件包及示例工作流
Model Details
- Type
- Generic Asset
- Subtype
- Workflows
- Created
- Updated
- July 7, 2026