Model Information






Description
The module already has VAE. Unless you have specific coloring requirements, it is recommended to use the VAE inside the module. Due to the unique nature of v-pred, I have created a dedicated section for v-pred.
Recommended Parameters:
Samplers: DDPM(suggest) > Euler > DDIM (⚠️ Other samplers will not work properly)
DDPM
CFG: 5.5 ( around 5.5)
Steps: 40 ( or higher)
Hi-res fix: Upscale 1.5x or higher, Denoising strength 0.15–0.45
Euler
CFG: 4~7
Steps: 20~35
Hi-res fix: Upscale 1.5x or higher, Denoising strength 0.15–0.45
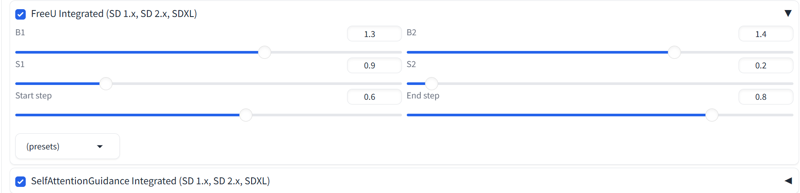
Forge Configuration Guide (Update to the latest version):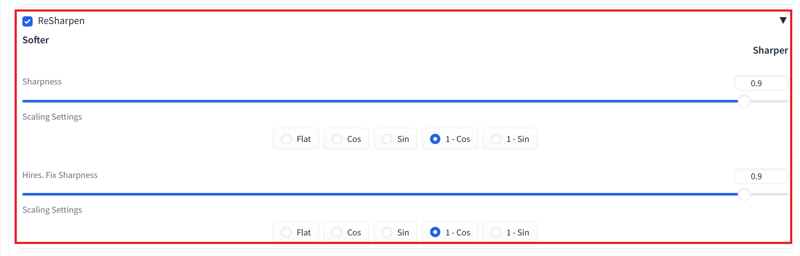 Select SDXL from FreeU dropdown menu, set the start to 0.6 and end to 0.8.( V2.0 Not recommended SelfAttentionGuidance Integrated )
Select SDXL from FreeU dropdown menu, set the start to 0.6 and end to 0.8.( V2.0 Not recommended SelfAttentionGuidance Integrated )
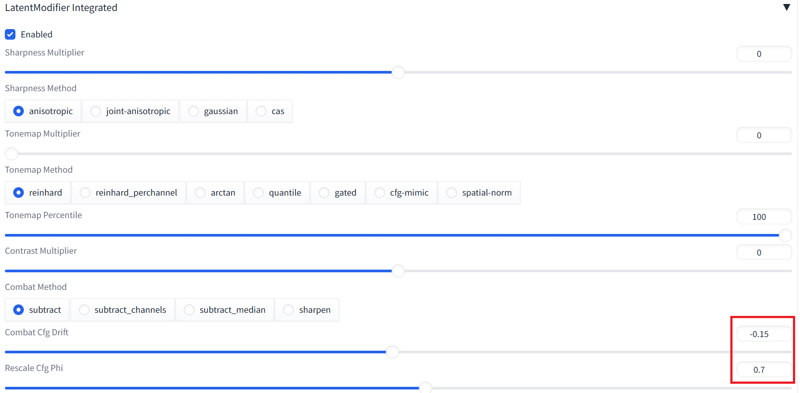 ComfyUI :
ComfyUI :
https://huggingface.co/Laxhar/noobai-XL-Vpred-0.5/blob/main/comfy_ui_workflow_sample.png
For Training v-pred LoRAs :
https://civitai.com/articles/8723/vlora-or-how-to-train-a-lora-on-v-pred-sdxl-model
Adetailer :
https://github.com/Bing-su/adetailer
Indigo Void Furry Vpred / Furry NoobAI V-pred
Model Details
- Type
- AI Model
- Task
- text-to-image
- Subtype
- Safetensors / Checkpoint AI Model
- Created
- Updated
- July 22, 2026