Model Information
.jpeg&w=1920&q=75)
.jpeg&w=1920&q=75)
.jpeg&w=1920&q=75)
.jpeg&w=1920&q=75)
.jpeg&w=1920&q=75)
.jpeg&w=1920&q=75)
Description
Qwen-image Merger
This is the Qwen-image version.
For now, I'm only uploading the simple version.
Is there demand for the full version?
Since HiDream, I've been struggling with the size of the models. I asked ChatGPT if it was possible to download them in parts, and they said it was. So I created this as a prototype for the part version. It still uses about 10GB of VRAM. It also uses a fair amount of main memory, so be careful.
FP8 is supported, but GGUF is not.
FluxMerger Chunked (for Low VRAM)
This version uses less VRAM. It uses more main memory. The VRAM usage at the time of merging is about 11GB when using a full-sized T5. However, when passed to KSsampler in the workflow, it consumes VRAM at BF16 size (about 27GB). To check the results, it is faster to save the model immediately before sampler and restart ComfyUI. Restart is performed from ComfyUI Manager.
In order to reduce memory consumption, the layers are further divided into chunks for processing, but this does not improve the effect. In fact, it may have a slight adverse effect.
Note: This version uses more main memory instead of less VRAM, resulting in slower merging. Use this version only if you don't have enough VRAM with the standard version.
SD15 FineMerger
This is the SD1.5 ComfyUI model merge node. It's been simplified based on lessons learned from SDXL.
Functionally, it's almost identical to previous models. You can specify weights for each layer and merge using weighted, adddiff, and traindiff. It also has some new features:
You can apply a global scaling factor to attn1 and attn2 for the entire model.
You can adjust the scaling factors for IN and OUT layers simultaneously (as I understand it, MID is IN12).
Personally, I find these to be very useful features. If you only want to increase the OUT attn1, use a multi-stage approach.
The example workflow uses five models and three block mergers. With traindiff, which is likely to use the most memory, displaying slightly larger images in four batches, the maximum VRAM usage was 17GB. However, even with the model and node caches cleared, it still used 6GB, so the actual usage was around 11GB.
I put it together just to check the operation, but looking at the sample workflow now, it seems very strange... This model is more meaningful than the other examples, but it initially involved adding elements of NAI2 to Beyond, which was created before the release of NAI2, and then mixing in a negative traindiff of the lower layers of SimpleRetro, which was done in an experiment to enhance Astaroth's photographic expression. The values used are extremely large and small, but in actual use, more modest values are safer.
SDXL FineMerger
This is the SDXL 1.0 version of the model merger.
Actually, I've barely used SDXL, so I don't really understand the key points. The model configuration is also extreme, and the granularity of the layers is so different that it was a mystery to me how everyone controlled it. After playing around with it a bit this time, I noticed that what used to take three layers to process in SD15 can now be done in one layer, so I could feel the improvement.
SDXL can also use SuperMerger, ComfyUI already has a SDXL block merge node, and the number of parameters is not so great that a Simple version is necessary. This time, contrary to previous versions, I tried something that allows for more detailed control.
Below is the configuration of the main sliders.
time_embed.,label_emb.
input_blocks.0.(128)
input_blocks.1.(128)
input_blocks.2.(128)
input_blocks.3.(128)
input_blocks.4.(64)
input_blocks.4.B0.(64)
input_blocks.4.B1.(64)
input_blocks.5.(64)
input_blocks.5.B0.(64)
input_blocks.5.B1.(64)
input_blocks.6.(64)
input_blocks.7.(32)
input_blocks.7.B0-2.(32)
input_blocks.7.B3-5 .(32)
input_blocks.7.B6-9.(32)
input_blocks.8.(32)
input_blocks.8.B0-2.(32)
input_blocks.8.B3-5.(32)
input_blocks.8.B6-9.(32)
middle_block.0.(32)
middle_block.1.(32)
middle_block.1.B0-2.(32)
middle_block.1.B3-5.(32)
middle_block.1.B6-9.(32)
middle_block.2.(32)
middle_block.2.B0-2.(32)
middle_block.2.B3-5.(32)
middle_block .2.B6-9.(32)
output_blocks.0.(32)
output_blocks.0.B0-2.(32)
output_blocks.0.B3-5.(32)
output_blocks.0.B6-9.(32)
output_blocks.1.(32)
output_blocks.1.B0-2.(32)
output_blocks.1.B3-5.(32)
output_blocks.1.B6-9.(32)
output_blocks.2.(32)
output_blocks.2.B0-2.(32)
output_blocks.2.B3-5.(32)
output_blocks.2.B6-9.(32)
output_blocks .3.(64)
output_blocks.3.B0.(64)
output_blocks.3.B1.(64)
output_blocks.4.(64)
output_blocks.4.B0.(64)
output_blocks.4.B1.(64)
output_blocks.5.(64)
output_blocks.5.B0.(64)
output_blocks.5.B1.(64)
output_blocks.6.(128)
output_blocks.7.(128)
output_blocks.8.(128)
out,sampling_sigma,noise_augmentor.
Settings that don't seem to be worth adjusting have been grouped together. You can specify weights for each sub-block within a layer. These can be used individually, and even this alone provides more precise control than previous mergers. Also, the number in parentheses is the size of the image handled by that layer in Unet. Personally, I added it because I think knowing this will allow you to figure out the rest.
However, because the level of detail has been reduced by one level, it will only be more rough than SD1.5 unless you supplement it with the Transformer layer. Here, the 10-stage Vision Transformer is grouped into three stages, allowing you to specify weights.
In addition, a second slider can also be connected. The second slider is specialized for a certain Transformer layer, and allows you to specify the attn1, attn2, and ff/norm ratios. The value applied is multiplied by the first slider. The alpha value obtained using these can be merged in three modes: Weighted (normal merge), AddDifference, and TrainDifference. The handling of the alpha value and merge mode are based on SuperMerger (the alpha value is reversed from that in ComfyUI, with 0 and 1).
Merging is possible without using a controller node, and the default value of the controller node slider is 1 (= no action), so just adjust the settings you want to change.
input_blocks.4.attn1
input_blocks.4.attn2
input_blocks.4.ffnorm
input_blocks.5.attn1
input_blocks.5.attn2
input_blocks.5.ffnorm
input_blocks.7.attn1
input_blocks.7.attn2
input_blocks.7.ffnorm
input_blocks.8.attn1
input_blocks.8.attn2
input_blocks.8.ffnorm
middle_block.1.attn1
middle_block.1.attn2
middle_block.1.ffnorm
middle_block.2.attn1
middle_block.2.attn2
middle_block.2.ffnorm
output_blocks.0.attn1
output_blocks.0.a ttn2
output_blocks.0.ffnorm
output_blocks.1.attn1
output_blocks.1.attn2
output_blocks.1.ffnorm
output_blocks.2.attn1
output_blocks.2.attn2
output_blocks.2.ffnorm
output_blocks.3.attn1
output_blocks.3.attn2
output_blocks.3.ffnorm
output_blocks.4.attn1
output_blocks.4.attn2
output_blocks.4.ffnorm
output_blocks.5.attn1
output_blocks.5.attn2
output_blocks.5.ffnorm
After creating this, I thought it might be a bit too detailed. I created it to test the slider linkage method, but if you are not satisfied with ComfyUI's merge node, please try using it.
HiDream DeltaLoRA tool
The HiDream model was too large to create a merge tool on ComfyUI.
Instead, I created a tool to create a differential LoRA from two models. This does not require as much memory. However, even if we only use DoubleBlocks and SingleBlock out of the total 1615 layers, the size of the LoRA would be enormous if we were to take the difference between all layers, so please use it to extract only a very limited number of layers. The MODEL output from this tool takes the differences into account, so by saving it, you can obtain a model that resembles a partially merged model. For finer adjustments, use it as LoRA and set the strength.
Note that this tool is for CUDA use only. FP8 (e4m3en, etc.) can also be used as the input file, but it will be processed internally in BF16. If your GPU does not support BF16, it will be converted to FP32.
*If you want to perform the process continuously, please press the "Free model and node cache" button in ComfyUI Manager.
Flux.1 Merger
When I previously announced SimpleFluxMerger, I was only using Schnell at the time, so I wasn't sure whether it was properly compatible with the dev version. After that, ComfyUI's memory-related behavior became unstable, and even generating images became difficult with the 16GB card I had at the time.
This problem continues to this day. Unlike back then, when it ran smoothly even if I created it without much thought, it now runs slowly even if I put a lot of thought into it. You need at least a GPU that can use Flux.1 and 64GB of main memory.
About 30GB of VRAM is used during merging. It's designed to be compatible with the RTX 5090, but it still uses that much (I also created a slower version that uses almost no VRAM, but it's very slow). I think that in many environments, 30GB of shared GPU memory will allow it to run.
Like the Chroma version, there is a full version and a simple version, and each has three nodes with different initial values.
Most of the points to note are the same as the Chroma version.
Some screenshots use SamplerCustomAdvanced, but it uses a lot of memory, so it is safer to use KSampler for merging.
 *sample of TrainDifference behavior
*sample of TrainDifference behavior
ChromaMerger
Since there are few Chroma-related tools, I created this merge node for ComfyUI.
It allows block merging of all Chroma layers. The slider range is -1 to 2, and it has modes equivalent to AddDifference and TrainDifference.
For CUDA only. Please keep ComfyUI up to date.
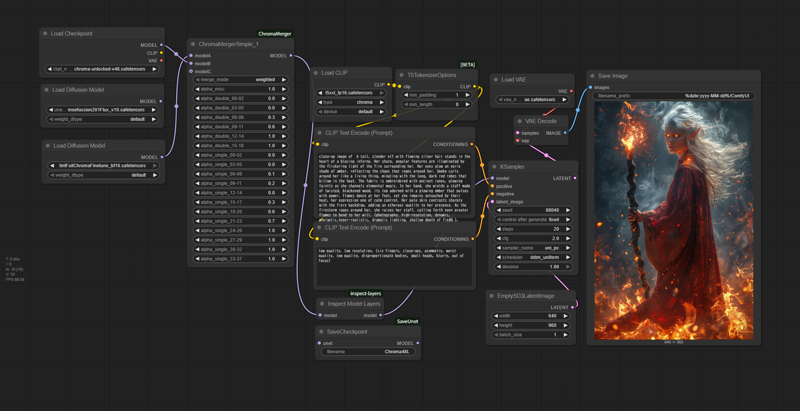 *Simple version
*Simple version
There are three versions of each: the regular version (66 sliders) and the simple version (19 sliders), but they all work the same except for the initial slider values. Changing the slider values manually can be a hassle, so if you want to change them all at once, just load the version with new initial values.
Additional tools are also included: one that displays the model configuration to the console, and one that saves the Unet part of the model as a Checkpoint (in a format that can be read by Checkpoint Loader). These are not required, but can be useful.
Note:
The slider values are based on SuperMerger and others. α=1 sets Model B to 100%. This is the opposite of ComfyUI.
GGUF cannot be used (probably NF4 as well?). Due to delayed loading, the file itself could not be accessed after loading the model, so information could not be retrieved correctly. Please expand it to a normal safetensors file beforehand (see: https://github.com/purinnohito/gguf_to_safetensors).
The models released as Chroma contain a mixture of several different tensor shapes. I was aiming for automatic adjustment, but it consumed too much memory and caused problems with the merger, so I gave up on this. I have also uploaded a tool for checking tensor shapes.
It consumes a large amount of both main memory and VRAM. It's supposed to be more compact than Flux.1, but Flux.1 doesn't consume as much memory because all internal processing is done in BF16. ChromaMerger uses BF16 to reduce memory consumption, but it requires more VRAM than Flux.1, likely due to FP32 expansion in samplers and other programs. The memory leak warning is apparently normal. It uses about 45GB of shared memory in total, so please check the capacity in advance.
The model specified as model B is placed in VRAM (A and C are main memory). Please check the GPU memory capacity and the size of the BF16-ized model (usually around 11GB).
It will consume even more memory from the second time onwards. This is apparently normal ComfyUI behavior, but please be aware that previously used models remain in VRAM, which will slow down the sampler in particular. It's usually faster to restart ComfyUI. If you're using ComfyUI Manager, be sure to press the "Free model and node cache" button before proceeding.
The development environment is 64GB of main memory + 32GB of VRAM. Operation on low-memory GPUs cannot be guaranteed. The code is primarily output by ChatGPT 4.1. If you encounter any problems, please submit the code to ChatGPT and ask for help.
Various issues have arisen that did not occur with Flux.1. As a result, although the usage environment is limited and usability is not great, it is now possible to perform minimum processing.
Please note that if you use LoRA on Flux.1, the license from that platform will likely apply.
ModelMerger for ComfyUI (Chroma/Flux.1/SDXL/SD1.5/Qwen-image)
Model Details
- Type
- Generic Asset
- Subtype
- Other
- Created
- Updated
- July 7, 2026