Model Information






Description
a semi-Realistic(2.5D) Pony-diffusion based Mixed model
This is another open/free merged model named Pinkie Pie pony mix
Early Access
I've activate Early Access just for fun :)
but you don't have to donate buzz. after 7 days it will be available automatically soon!
some version descriptions
v2.2 - high details, ~ 2.5D
v3.3 - (based on v2.2) - ~2.8D more contrast, less details, hires fix needed.
v3.4 - (based on v2.2) - ~2.8D reduce details, for normal use.
v3.5 ALT - (based on v2.2) - ~2.8D. slightly fixed text-encoder issue.
v3.6 - (based on v3.5 ALT) - ~2.8D. slightly fixed face and style
Merged Models
tangbohu-lofi-pony-basemodel (by @tangbohu) to enhance basis model (a trained model)
yaminabepony (by @KKTT6783 ) to add pretty asian face style. (a trained model)
MIST XL Hyper Character Style Model AiARTiST by @AiARTiST (used to fix details: block "out." level for v2.0 and v3.1) (a trained model)
White_RealisticSimulator_Pony by @white2023 for asian style face (v3.0) (a trained model)
xxmix9 realistic SDXL by @Zyx_xx for asian style face (v3.1 and v3.6) (a trained model)
Raemora XL v2.0 by @Raelina (fix for v3.5 ALT text encoder)
Recipes of the v1.0
Model Mixer https://github.com/wkpark/sd-webui-model-mixer is used to mix all models in one step. recipe details are included in the model checkpoint or some images. (so you can use/modify this recpie easily by using the model-mixer)
VAE included.
all recipes of each version are included in the checkpoint metadata!
This is a screenshot of sd-webui with the model-mixer extension:
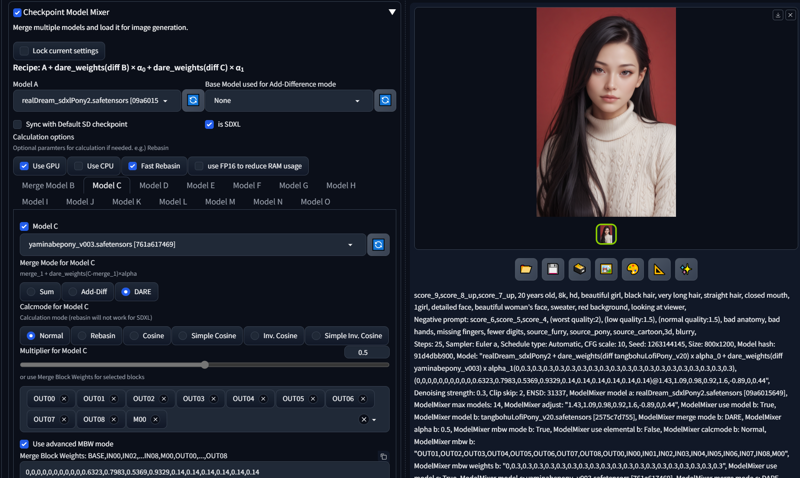
The basic recipe is the follow
step #1 : base model A + model B x 0.3 = mix_A (text encoder excluded) DARE merge method (a simplified DARE method is supported by the model-mixer)
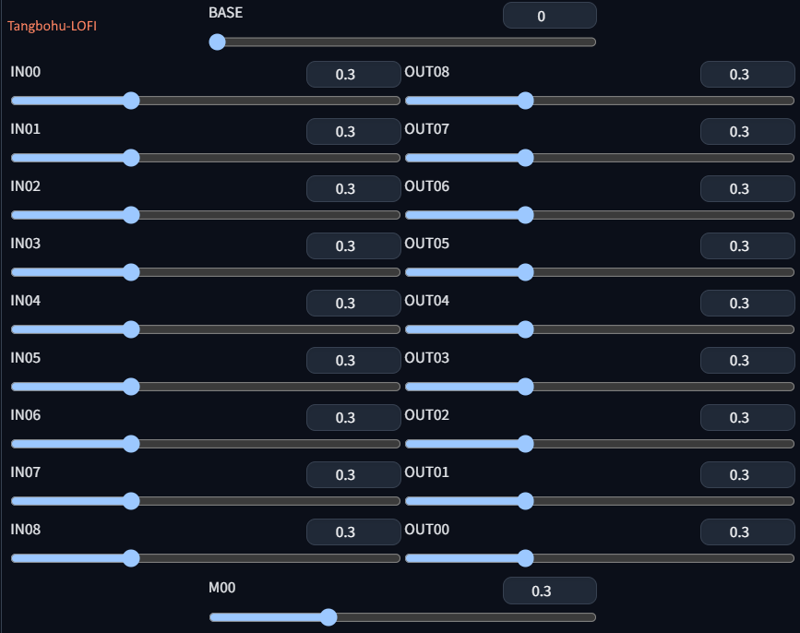 - after some trial and error,
- after some trial and error, OUT01reduced from0.3to0.1step #2 : block level mix - mix_A + model C = final mix - DARE merge method
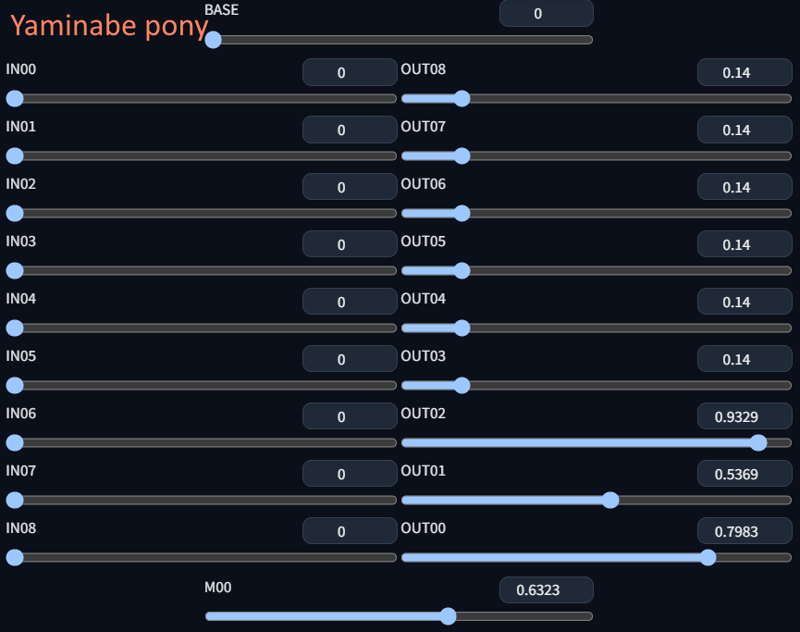 - explain: block level merges on MID + OUT00~OUT08.
- explain: block level merges on MID + OUT00~OUT08.- SDXL OUT00 ~ OUT02 blocks have a wide effect, especially on the face style.
- NOTE: DARE method uses random pivoting internally, so the results may be slightly different in each merge process.
Adjust settings: this is the adjust settings to optimize the details and tone of model ,
time_embed.*andout.*weights have been tuned (please see https://github.com/hako-mikan/sd-webui-supermerger?tab=readme-ov-file#adjust)
Recommends
All posted images use μ-DDetailer script extension
recommended sampler: Euler a
recommended scheduler:"Align Your Steps" (from A1111 v1.9.x)
"Align Your Steps" scheduler works fine with another samplers.
recommended image size (width range is about 640~1024 / height range is 640~1344):
1024x1024 (default SDXL)
640x960 / 768x1152 / 800x1200
832x1216 / 896x1152
see also SDXL resolution cheat sheet: https://www.reddit.com/r/StableDiffusion/comments/15c3rf6/sdxl_resolution_cheat_sheet/
recommended CFG scale: 3~7
with Dynamic Threasholding (CFG Fix )
- CFG scale 10
- mimic cfg scale 3~7
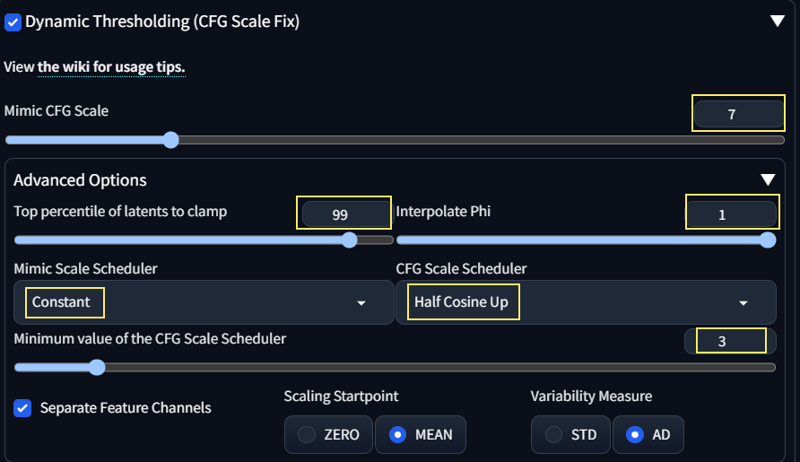
Set Clip skip: 2 recommended (Clip skip:1 also works fine), ENSD: 31337
use pony_negativeV2 (https://civitai.com/models/411532/ponynegative-for-pianomix)
in your negative prompt (pony_negativeV2 by @Piano_AI )
Useful AUTOMATIC1111's webui extensions
the following sd-webui extensions are recommended.
or use famous ADetailer extension
civitai extension to add several useful features for civitai.
ChangeLog
2024/05/16 - first release out
2024/05/18 - v1.3 released with minor text-encoder fixes. (full rebuild)
specific text-encoder weights replaced with the yaminabepony 's BASE
BASE:layers.1.*, BASE:resblocks.5.* have some bug and replaced.
more weight level bugs will be fixed soon☕👀
2024/05/26 - v1.4 released with minor text-encoder fixes. (v1.0 + additional text-encoder fixes)
v1.4 = v1.0 + additional text-encoder fixes with yaminabepony's text-encoder.
BASE:layers.1.* with 1.0 weights (DARE merge)
BASE:resblocks.1.* with 0.2 weights (DARE merge)
BASE:resblocks:5.* with 1.0 weights (DARE merge)
2024/06/08 - v1.5 released with minor text-encoder fixes (+brightness adjusted)
2024/06/08 - v1.6 released with minor text-encoder fixes (v1.5 hot fix)
2024/06/08 - v2.0 released with "OUT08" block level fix. (with MIST checkpoint . enhanced details)
2024/06/13 - v2.1 released with optimized details using adjust parameters (without MIST checkpoint)
2024/06/15 - v2.2 released with text-encoder fixes (v2.1 + text-encoder fixes)
2024/06/21 - v3.0 released with face style fix (use v2.2 as a basis + block level merge with the white_v2.0 model + more yaminabepony v3 block level merge )
2024/06/29 - v3.1 released with face style fix (more block level tuning + additionally merge models xxmix + mist)
2024/07/12 - v3.2 released with text-encoder fixes (text_l replaced with MIST's, text_g fixes with yaminabepony's
token_embedding.weight,minor fix the adjust details.2024/07/20 - v3.3 released. fix text-encoder + block level Unet fix for "realistic" + "photo" prompts. (hires fix highly recommended)
2024/07/21 - v3.4 released. reduced details/noise of the v3.3 for normal use without hires fix.
2024/08/03 - v3.5-alt released. try to fix text-encoder to fix "realistic", "photo" prompts related issue.
2024/12/13 - v3.6 released with minor face style fix (using xxmix9)
TODO
add more realistic skin tone
optimize details adjust parameters for more realistic with high details (v2.x)reduce western style face,more asian style face (v3.x)fix detail levels (v2.x)
Known Bugs
(v1.0~) With some prompts it produce ziggling images for example:

and the cause of this error is the text-encoder of the original models (in this case the RealDream Pony v2 produce exactly the same error under A1111.) this issue slightly fixed in the v1.2 merged model.
This issue was suspected to be an error with a specific weights and was resolved by replacing specific CLIP weights.
(this issue resolved in the RealDream Pony v3)
2. Some prompt words make the generated images look a bit somewhat cartoonish and ugly: e.g.) large eys, grin, ...
License
All used models here have "Have different permissions when sharing merges" license permission, so I do not add additional restrictions on it.
The original Pony-diffusion v4 license disclaim "Same license restriction" so I do not add any restriction except same license restriction. (Please see https://huggingface.co/AstraliteHeart/pony-diffusion-v4 and https://huggingface.co/spaces/CompVis/stable-diffusion-license)
This model permits users to:
✔Use the model without crediting the creator
✔Sell images they generate
✔Run on services that generate images for money
✔Share merges using this model
✔Sell this model or merges using this model
❌Have different permissions when sharing merges
Specifically, the OpenRAIL-M license permits users to own the rights to the images they generate and to use these images for commercial purposes (Stable Diffusion) (Baseten). This openness supports a wide range of applications, from creative projects to commercial services, enabling businesses and individuals to leverage the model's capabilities for various purposes.
Therefore, if you're considering using Stable Diffusion for commercial products or services, the licensing terms do support such use, as long as the guidelines and restrictions outlined in the license are followed. (from chatgpt)
Support me
If you like my work, feel free to buy me a coffee at ko-fi. https://ko-fi.com/mixboy
PinkiePie pony mix
Model Details
- Type
- AI Model
- Task
- text-to-image
- Subtype
- Safetensors / Checkpoint AI Model
- Created
- Updated
- July 17, 2026