Model Information






Description
- Follow for more updates at http://discord.com/invite/TTTGccjbEa
- Try Model: Huggingface Playground
- Access to more ongoing training versions
- 中文模型说明
- QQ group: 1039442542

Introduction
Neta Lumina is a high‑quality anime‑style image‑generation model developed by Neta.art Lab.
Building on the open‑source Lumina‑Image‑2.0 released by the Alpha‑VLLM team at Shanghai AI Laboratory, we fine‑tuned the model with a vast corpus of high‑quality anime images and multilingual tag data. The preliminary result is a compelling model with powerful comprehension and interpretation abilities (thanks to Gemma text encoder), ideal for illustration, posters, storyboards, character design, and more.
Key Features
Optimized for diverse creative scenarios such as Furry, Guofeng (traditional‑Chinese aesthetics), pets, etc.
Wide coverage of characters and styles, from popular to niche concepts. (Still support danbooru tags!)
Accurate natural‑language understanding with excellent adherence to complex prompts.
Native multilingual support, with Chinese, English, and Japanese recommended first.
Model Versions
For models in alpha tests, requst access at https://huggingface.co/neta-art/NetaLumina_Alpha if you are interested.
Neta-lumina-v1.0
Request access at https://huggingface.co/neta-art/Neta-Lumina if you are interested.
Official Release: overall best performance
Neta-lumina-beta-0624
Primary Goal: General knowledge and anime‑style optimization
Data Set: >13 million anime‑style images
>46,000 A100 Hours
How to Use
Neta Lumina is built on the Lumina2 Diffusion Transformer (DiT) framework, please follow these steps precisely.
ComfyUI
Environment Requirements
Currently Neta Lumina runs only on ComfyUI:
Latest ComfyUI installation
≥ 8 GB VRAM
Downloads & Installation
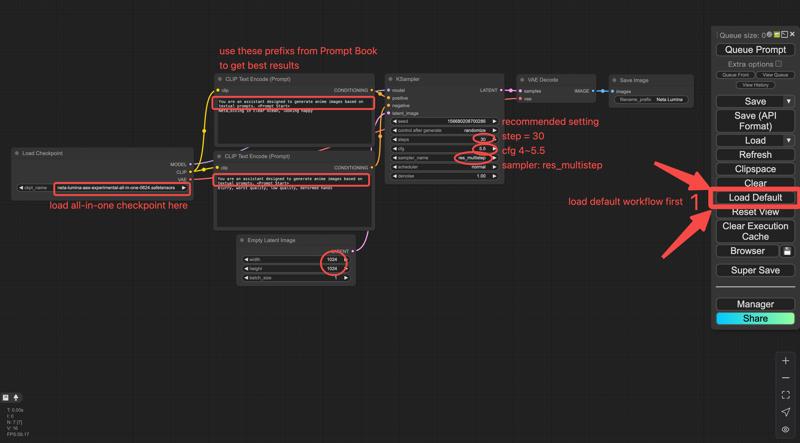
The model provided by Civitai is a three-in-one (te, dit, vae) packaged version, which can be run using the comfyui basic workflow without the need to download Text Encoder and VAE separately.
Original (component) release
Neta Lumina-V1.0
Hugging Face: https://huggingface.co/neta-art/Neta-Lumina/blob/main/Unet/neta-lumina-v1.0.safetensors
Save path:
ComfyUI/models/unet/
Text Encoder (Gemma-2B)
Download link: https://huggingface.co/neta-art/Neta-Lumina/blob/main/Text%20Encoder/gemma_2_2b_fp16.safetensors
Save path:
ComfyUI/models/text_encoders/
VAE Model (16-Channel FLUX VAE)
Download link: https://huggingface.co/neta-art/Neta-Lumina/blob/main/VAE/ae.safetensors
Save path:
ComfyUI/models/vae/
 Workflow: load lumina_workflow.json in ComfyUI.
Workflow: load lumina_workflow.json in ComfyUI.
UNETLoader – loads the .pth
VAELoader – loads ae.safetensors
CLIPLoader – loads gemma_2_2b_fp16.safetensors
Text Encoder – connects positive /negative prompts to the sampler
Simple merged release
Download neta-lumina-v1.0-all-in-one.safetensors,
md5sum = dca54fef3c64e942c1a62a741c4f9d8a,
you may use ComfyUI’s simple checkpoint loader workflow.
Recommended Settings
Sampler: res_multistep
Scheduler: linear_quadratic
Steps: 30
CFG (guidance): 4 – 5.5
EmptySD3LatentImage resolution: 1024 × 1024, 768 × 1532, 968 × 1322, or >= 1024
Prompt Book
Detailed prompt guidelines: https://civitai.com/articles/16274/neta-lumina-drawing-model-prompt-guide
Community
Discord: https://discord.com/invite/TTTGccjbEa
QQ group: 1039442542
Roadmap
Model
Continous base‑model training to raise reasoning capability.
Aesthetic‑dataset iteration to improve anatomy, background richness, and overall appealness.
Smarter, more versatile tagging tools to lower the creative barrier.
Ecosystem
LoRA training tutorials and components
Development of advanced control / style‑consistency features (e.g., Omini Control). Call for Collaboration!
License & Disclaimer
Neta Lumina is released under the Fair AI Public License 1.0‑SD
Any modifications, merges, or derivative models must themselves be open‑sourced.
Participants & Contributors
Special thanks to the Alpha‑VLLM team for open‑sourcing Lumina‑Image‑2.0
Partners
nebulae: Civitai ・ Hugging Face
narugo1992 & deepghs: open datasets, processing tools, and models
Community Contributors
Evaluators & developers: 二小姐, spawner, Rnglg2
Other contributors: 沉迷摸鱼, poi, AshenWitch, 十分无奈, GHOSTLX, wenaka, iiiiii, 年糕特工队, 恩匹希, 奶冻, mumu, yizyin, smile, Yang, 古神, 灵之药, LyloGummy, 雪时
Appendix & Resources
TeaCache: https://github.com/spawner1145/CUI-Lumina2-TeaCache
Advanced samplers & TeaCache guide (by spawner): https://docs.qq.com/doc/DZEFKb1ZrZVZiUmxw?nlc=1
Neta Lumina ComfyUI Manual (in Chinese): https://docs.qq.com/doc/DZEVQZFdtaERPdXVh
license: other
license_name: fair-ai-public-license-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
Neta Lumina
v1.0
Model Details
- Type
- AI Model
- Task
- text-to-image
- Subtype
- Safetensors / Checkpoint AI Model
- Created
- Updated
- May 28, 2026