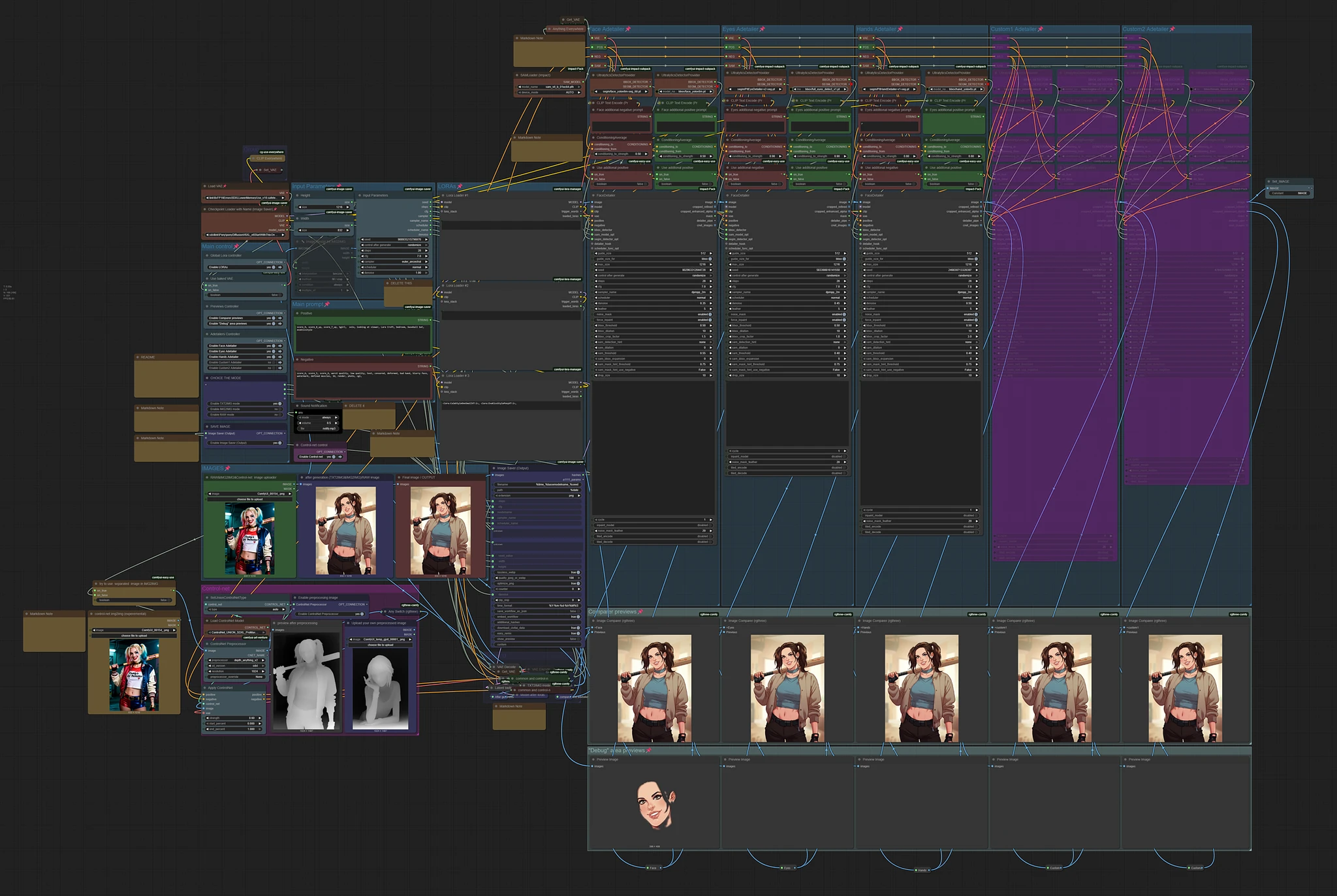

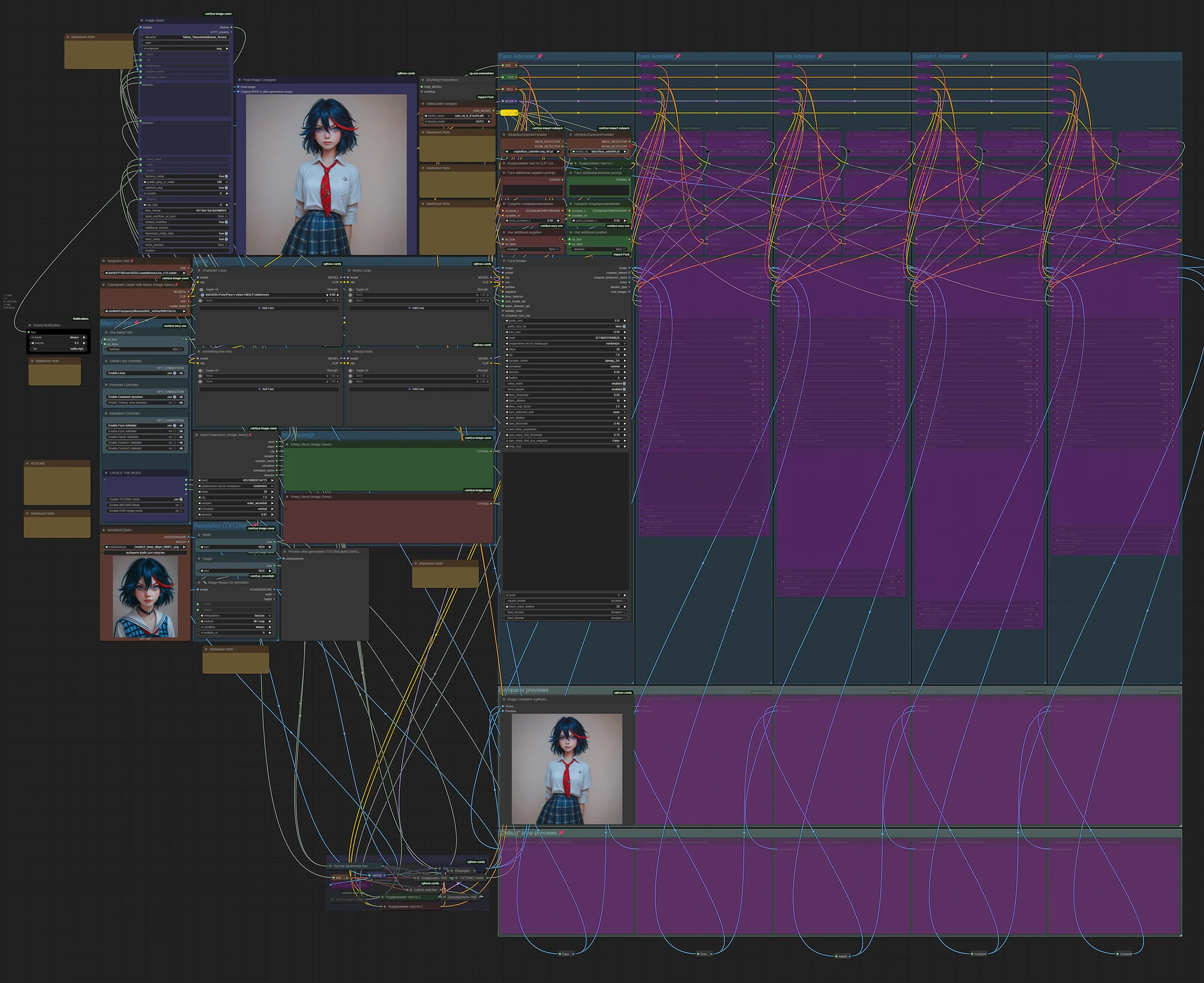

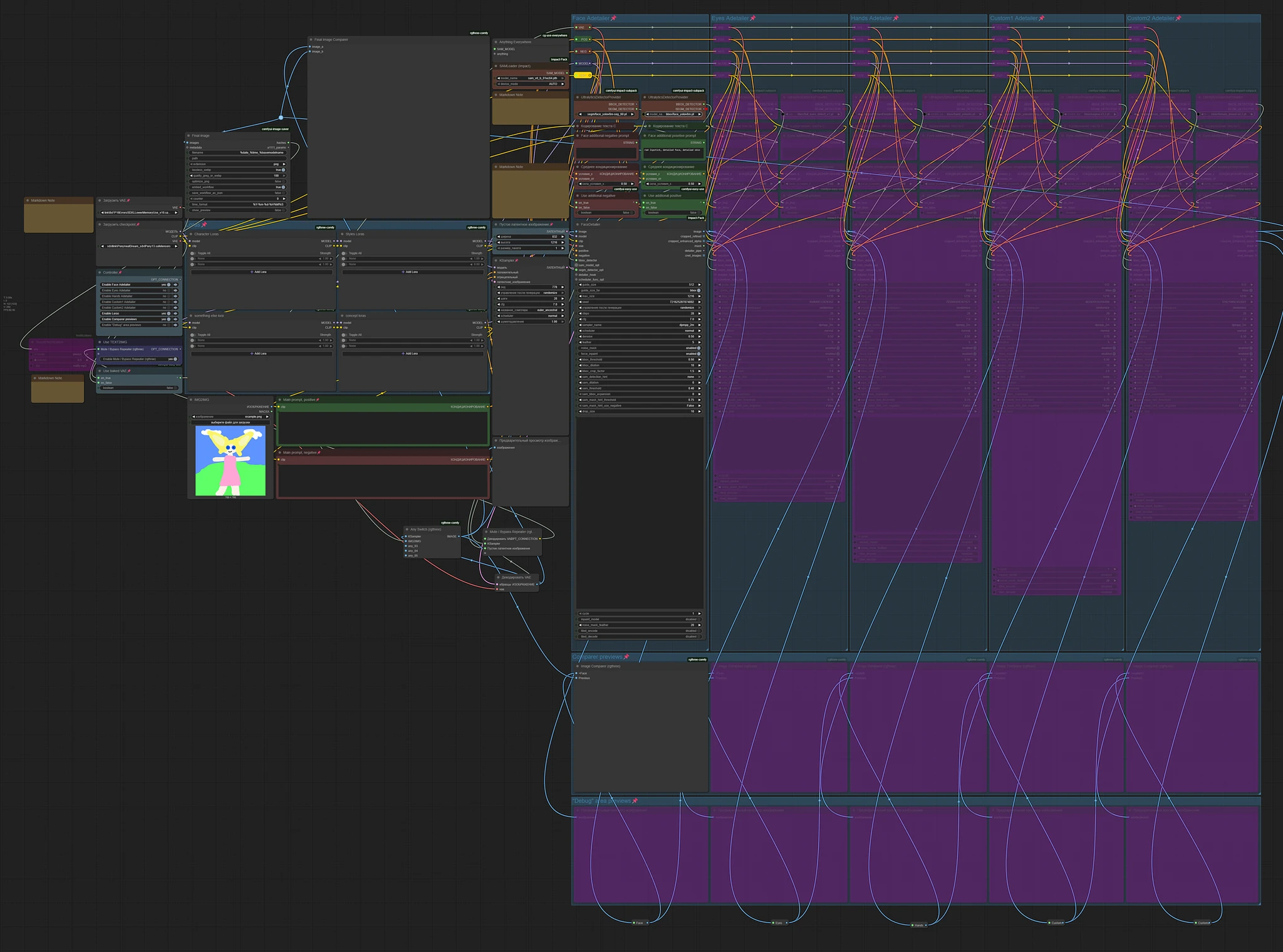
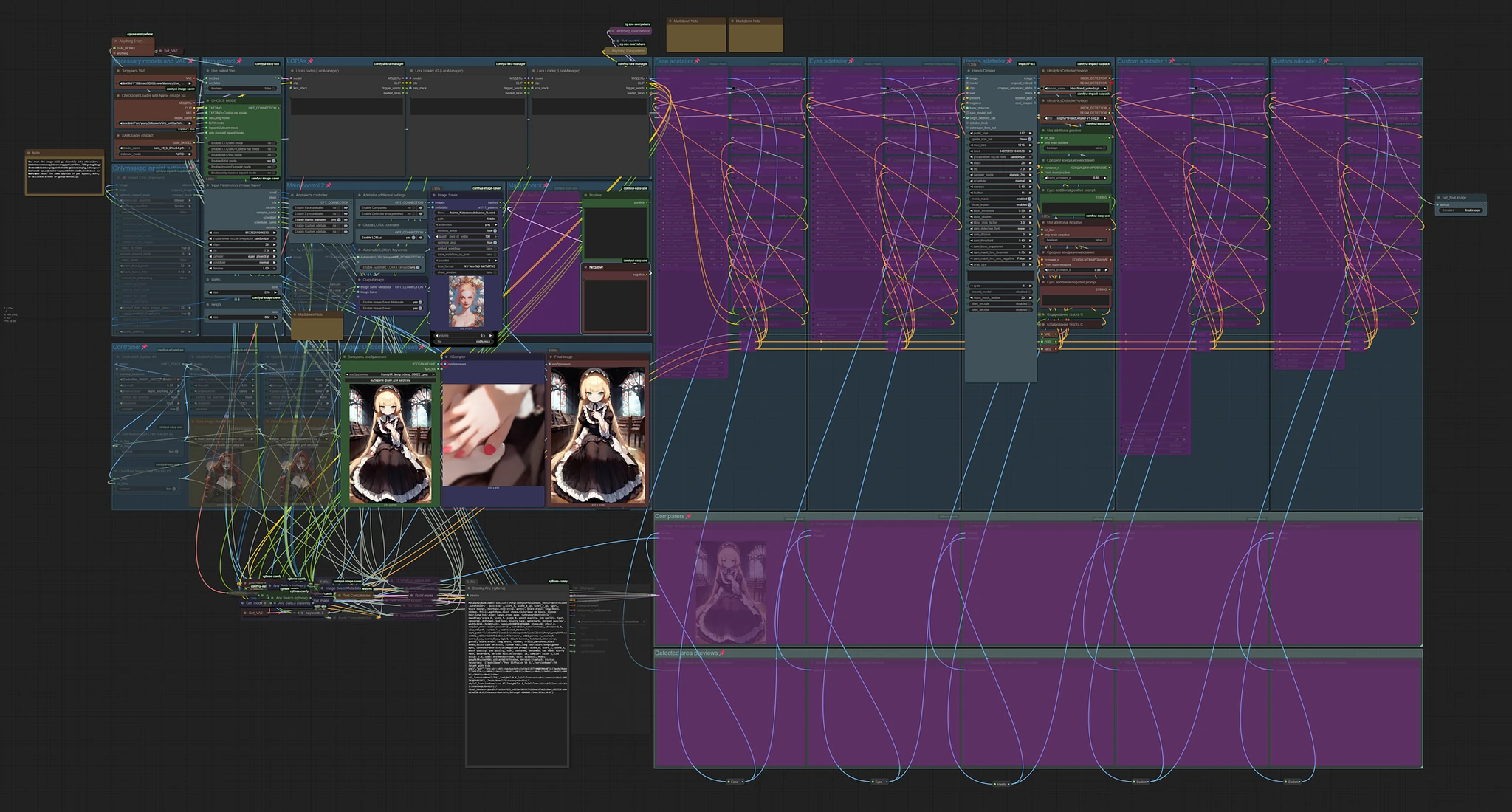
Main concept is from this workflow https://civitai.com/models/1507055/text-to-img-complete-workflow-multi-loras-adetailer-wildcards-and-more-comfyui by @Mittoshura.
I don't know Civita marking images as"Made on-site".
There is an issue in v3 that was not resolved. I will reupload it after making the corrections.
This is my first workflow, so don't expect too much. Especially about design, some decisions could be made in a better way. But everything on my test is working fine. The workflow is designed for a single image. I didn't test it for batches more then one.
Adding control-net support is in my plans. It's done.
If you have any issues, please let me know.
Yolo/segmentation models:
Popularity
Info
Latest version (v7.0): 1 File
About this version: v7.0
Removed the sam_model loader node;
Added support for deep danbooru captions and a toggle for it;
Added an 'reader' of metadata for uploaded images (it works great with images created with WebUI and ComfuUI without embedded workflow). The scenario for using both features is simply to choose raw mode and turn off all adetailers.
Turned back the adetailer's images on top of them, because the size of latent previews is unpredictable;
Added bookmarks for fast moving using Latin letters (not keys), check the note in the workflow;
Some small other changes.
8 Versions
Go ahead and upload yours!