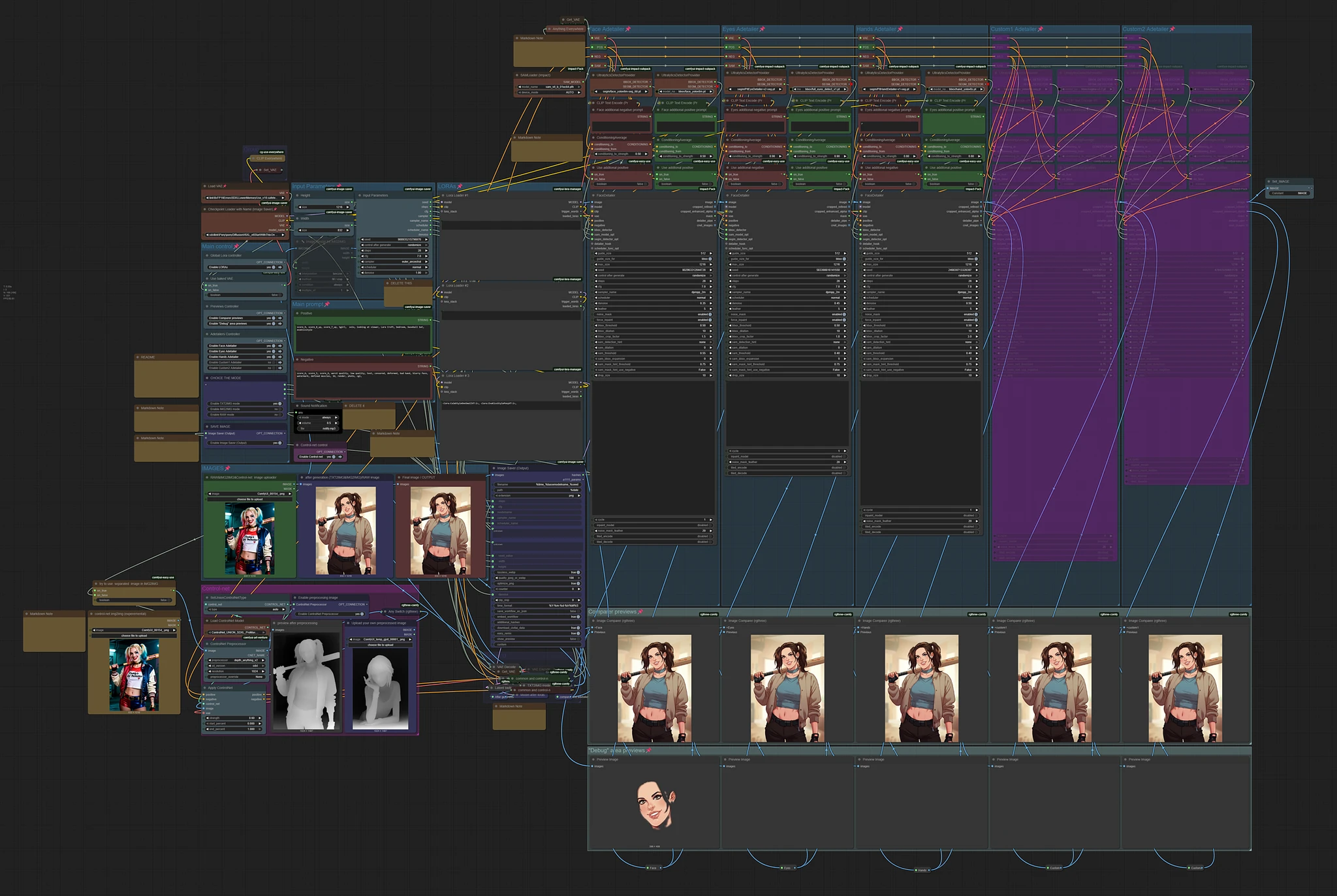

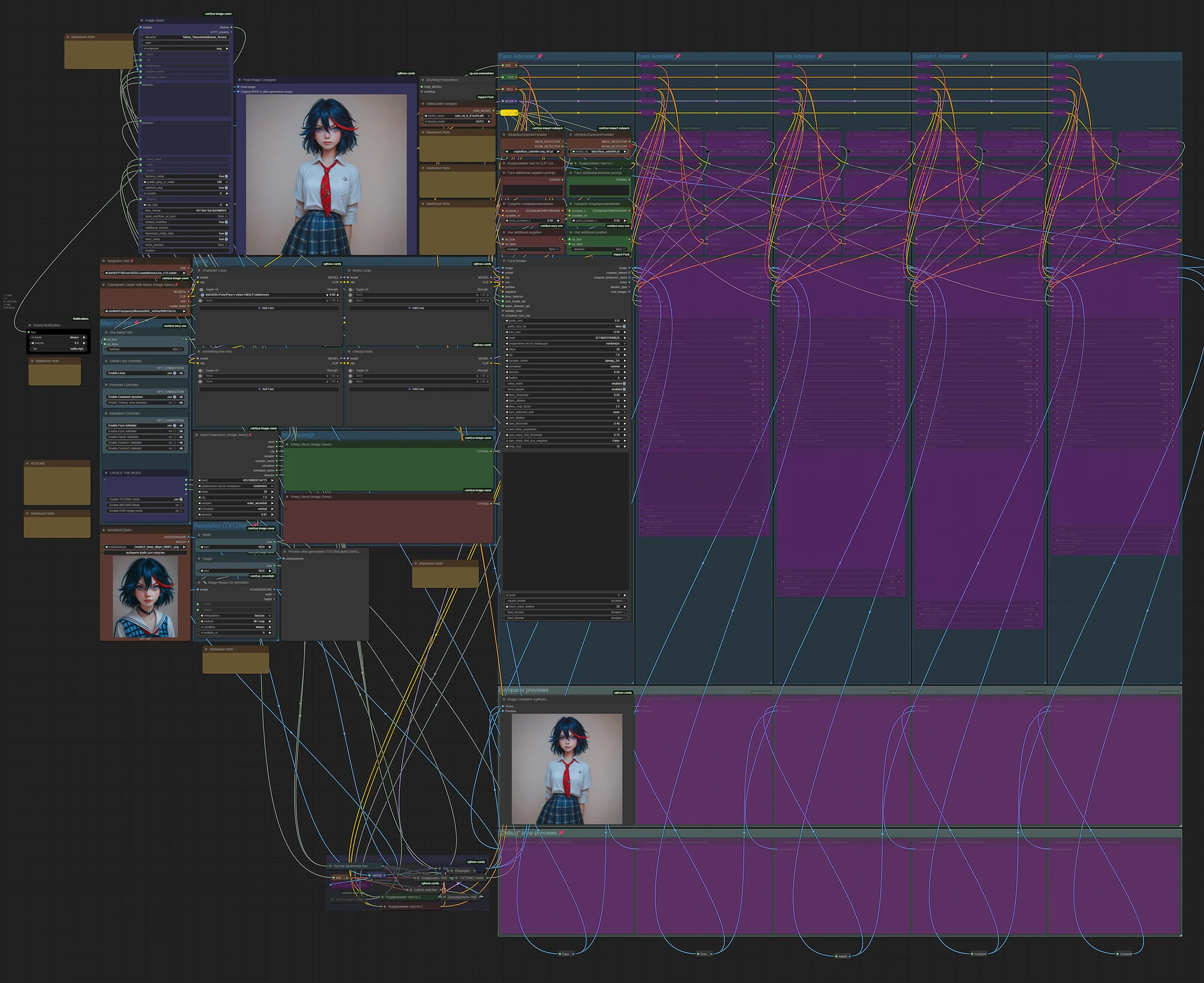

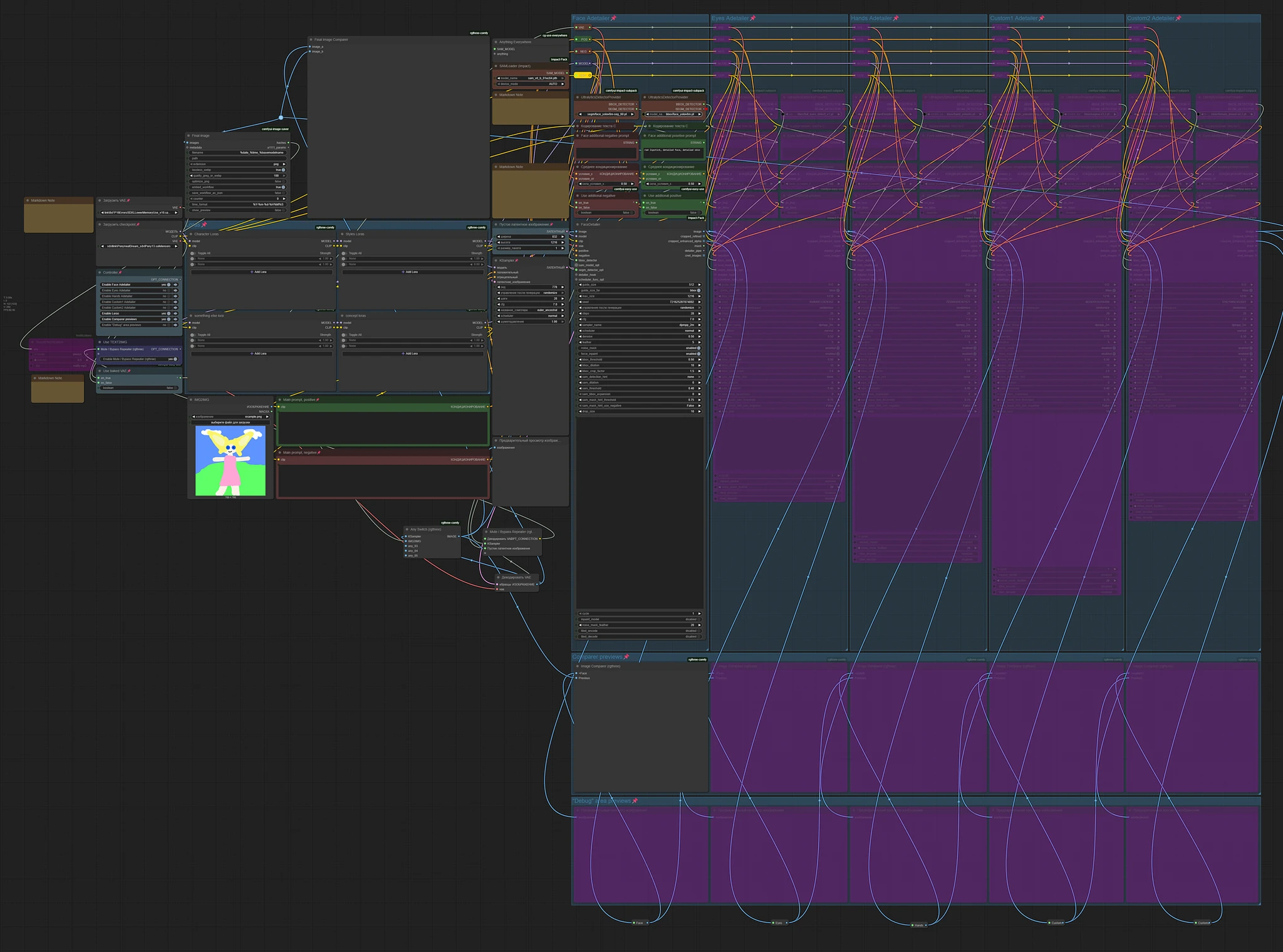
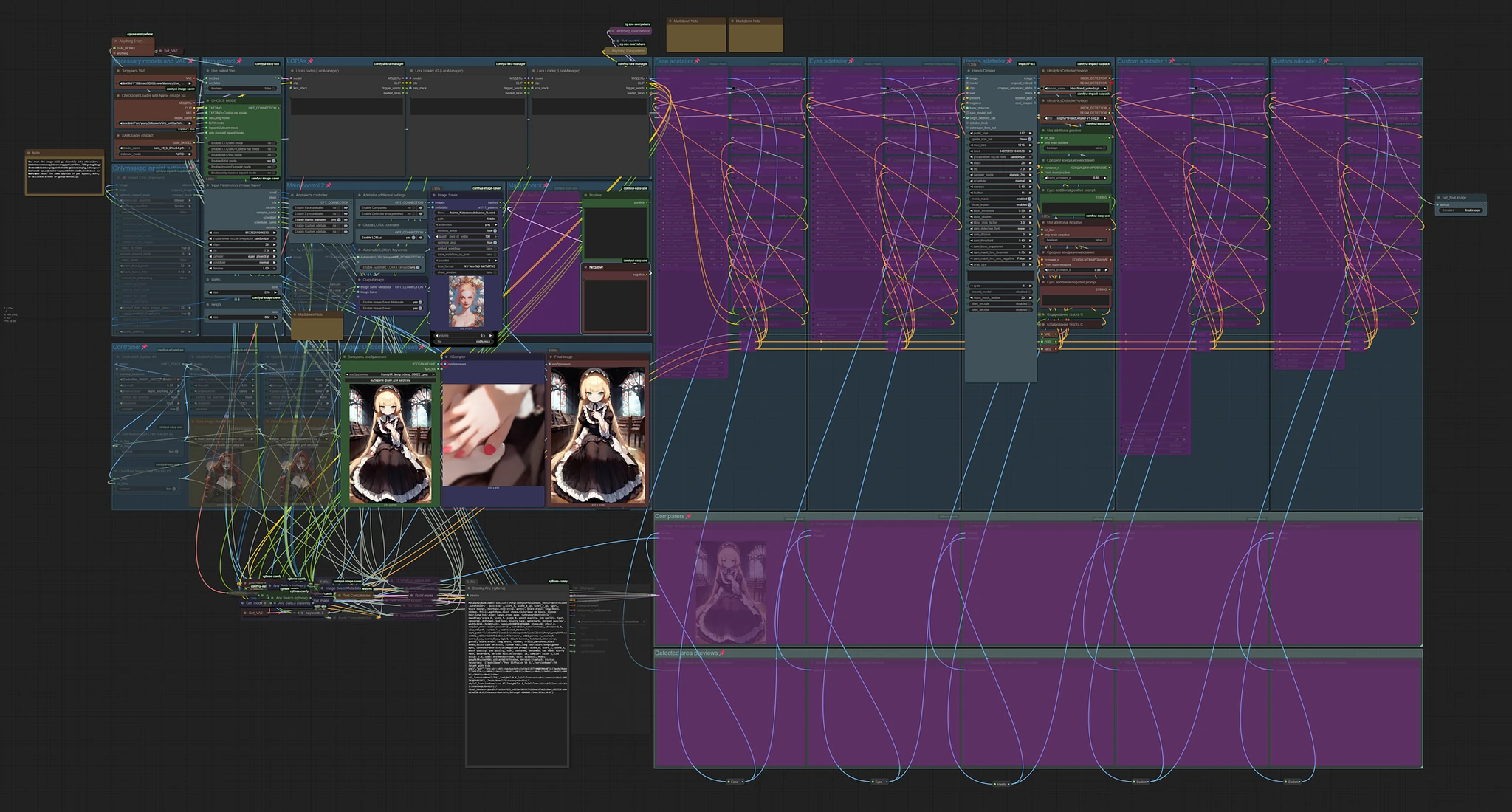
Main concept is from this workflow https://civitai.com/models/1507055/text-to-img-complete-workflow-multi-loras-adetailer-wildcards-and-more-comfyui by @Mittoshura.
I don't know Civita marking images as"Made on-site".
There is an issue in v3 that was not resolved. I will reupload it after making the corrections.
This is my first workflow, so don't expect too much. Especially about design, some decisions could be made in a better way. But everything on my test is working fine. The workflow is designed for a single image. I didn't test it for batches more then one.
Adding control-net support is in my plans. It's done.
If you have any issues, please let me know.
Yolo/segmentation models:
Popularity
Info
Version v6.0: 1 File
About this version: v6.0
Changed the checkpoint Lora, it will have a few cool features for Pony models: change positive and negative nodes, now they have button format like in vanilla WebUI A1111; add support for morphing like [cat|dog], segmentation and others; IPAdapter FaceID; write a damn huge readme (even so, nobody will read this, at least fully), add some display nodes and many other small changes.
8 Versions
Go ahead and upload yours!